
常见面试题
Java基础
字符
- 操作少量字符数据用 String;单线程操作大量数据用 StringBuilder;多线程操作大量数据用 StringBuffer。
String
- String 由 char[] 数组构成,使用了 final 修饰,对 String 进行改变时每次都会新生成一个 String 对象,然后把指针指向新的引用对象。
StringBuffer
- StringBuffer可变并且线程安全
StringBuilder
- StringBuilder可变但线程不安全。
equals
equals和==
- quals是Object的方法,默认比较的是对象的地址值。可以通过重写从而比较的对象的值。如String
- “==”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。
equals和hashCode
- hashCode()默认是通过地址来计算hash码,可以通过重写从而通过对象的值计算hash码
- 若两个对象相等,他们的hashCode和equals一定相等
- hashCode相等的两个对象未必相等
- 重写equals()必须重写hashCode(),比如在HashMap中,key如果是String类型,String如果只重写了equals()而没有重写hashcode()的话,则两个equals()比较为true的key,因为hashcode不同导致两个key没有出现在一个索引上,就会出现map中存在两个相同的key
HashMap
- HashMap在Jdk1.8以后是基于数组+链表+红黑树来实现的,特点是,key不能重复,可以为null,线程不安全
扩容机制
- HashMap的默认容量为16,默认的负载因子为0.75,当HashMap中元素个数超过容量乘以负载因子的个数时,就创建一个大小为前一次两倍的新数组,再将原来数组中的数据复制到新数组中。当数组长度到达64且链表长度大于8时,链表转为红黑树
存取原理
- 计算key的hash值,然后进行二次hash,根据二次hash结果找到对应的索引位置
- 如果这个位置有值,先进性equals比较,若结果为true则取代该元素,若结果为false,就使用高低位平移法将节点插入链表(JDK8以前使用头插法,但是头插法在并发扩容时可能会造成环形链表或数据丢失,而高低位平移发会发生数据覆盖的情况)
怎么用线程安全的HashMap
- 使用ConcurrentHashMap
- 使用HashTable
- Collections.synchronizedHashMap()方法
ConcurrentHashMap原如何保证的线程安全
- JDK1.7:使用分段锁,将一个Map分为了16个段,每个段都是一个小的hashmap,每次操作只对其中一个段加锁
- JDK1.8:采用CAS+Synchronized保证线程安全,每次插入数据时判断在当前数组下标是否是第一次插入,是就通过CAS方式插入,然后判断f.hash是否=-1,是的话就说明其他线程正在进行扩容,当前线程也会参与扩容;删除方法用了synchronized修饰,保证并发下移除元素安全
HashTable与HashMap的区别
- HashTable的每个方法都用synchronized修饰,因此是线程安全的,但同时读写效率很低
- HashTable的Key不允许为null
- HashTable只对key进行一次hash,HashMap进行了两次Hash
- HashTable底层使用的数组加链表
ArrayList
ArrayList和LinkedList的区别
- ArratList的底层使用动态数组,默认容量为10,当元素数量到达容量时,生成一个新的数组,大小为前一次的1.5倍,然后将原来的数组copy过来;因为数组在内存中是连续的地址,所以ArrayList查找数据更快,由于扩容机制添加数据效率更低
- LinkedList的底层使用链表,在内存中是离散的,没有扩容机制;LinkedList在查找数据时需要从头遍历,所以查找慢,但是添加数据效率更高
如何保证ArrayList的线程安全
- 使用collentions.synchronizedList()方法为ArrayList加锁
- 使用Vector,Vector底层与Arraylist相同,但是每个方法都由synchronized修饰,速度很慢
- 使用juc下的CopyOnWriterArrayList,该类实现了读操作不加锁,写操作时为list创建一个副本,期间其它线程读取的都是原本list,写操作都在副本中进行,写入完成后,再将指针指向副本。
反射
什么是反射
- 反射是通过获取类的class对象,然后动态的获取到这个类的内部结构(成员变量、方法、构造器等),从而动态的去操作类的属性和方法。
获取class对象的方法有
- class.forName(类路径)
- 类.class()
- 对象的getClass()
应用场景
- 做框架
- 要操作权限不够的类属性和方法时
- 实现自定义注解时
- 动态加载第三方jar包时
- 按需加载类
- 节省编译和初始化时间
其他
面向对象和面向过程的区别
- 面向对象有封装、继承、多态性的特性,所以相比面向过程易维护、易复用、易扩展
- 但是因为类调用时要实例化,所以开销大性能比面向过程低
多态的作用
- 多态的实现要有继承、重写,父类引用指向子类对象。
- 可以消除类型之间的耦合关系,增加类的可扩充性和灵活性。
Java创建对象得五种方式
- new
- Class.newInstance
- Constructor.newInstance
- Clone
- 反序列化
深拷贝和浅拷贝
- 浅拷贝:浅拷贝只复制某个对象的引用,而不复制对象本身,新旧对象还是共享同一块内存
- 深拷贝:深拷贝会创造一个一摸一样的对象,新对象和原对象不共享内存,修改新对象不会改变原对对象。
Java多线程
Mybatis
分页插件的原理
- 首先分页参数放到ThreadLocal中
- 拦截器拦截执行的sql,根据数据库类型添加对应的分页语句重写sql
例如
- select * from table where xxx 会转为 select count(*) from table where xxx 和 select * from where xxx limit
- 从而计算出total总条数、pageNum当前页码、pageSize每页大小、以及当前页数据、是否为首尾页、总页数等信息
ResultType和ResultMap
- ResultType:指定映射类型,只要查询的字段名和类型的属性名匹配可以自动映射。
- ResultMap:自定义映射规则,当查询的字段名和映射类型的属性不匹配时可以通过ResultMap自定义映射规则也可以实现一对多、—对一映射。
#{}和${}
- #{}:属于占位符,相当于?,可以防止sql注入
- ${}:用于在动态sql中拼接字符串,可能导致sql注入
cookie、session、token
cookie
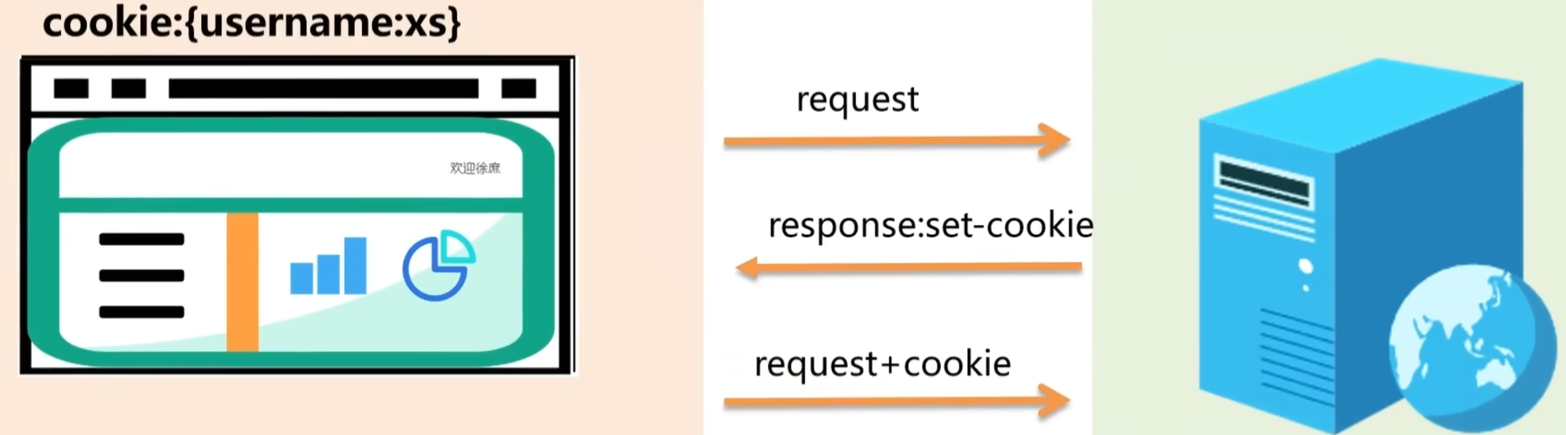
- 特点:存储在客户端、帮助在客户端和服务器之间维护状态信息
- 缺点:有被窜改的风险、容量限制为4kb,用户可以通过浏览器禁用cookie
session
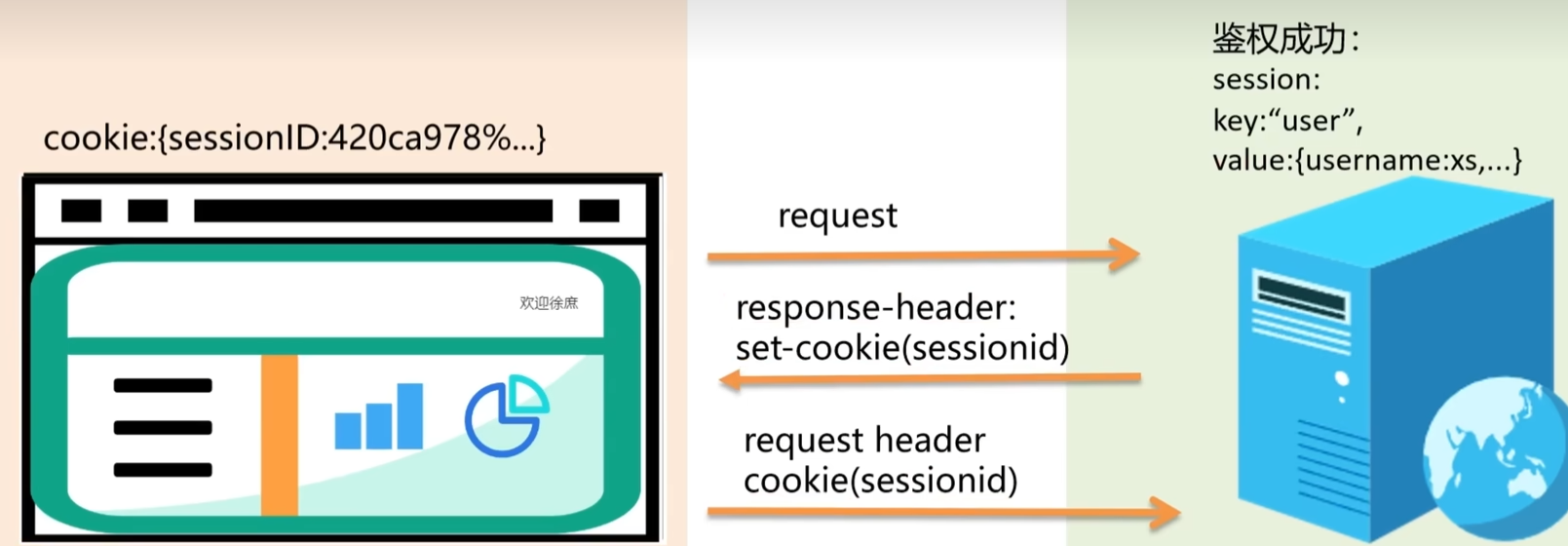
- 特点:存储在服务器、可以保存对象
- 缺点:占用服务器资源、扩展性差(分布式集群)、依然需要依赖cookie、存在跨越限制
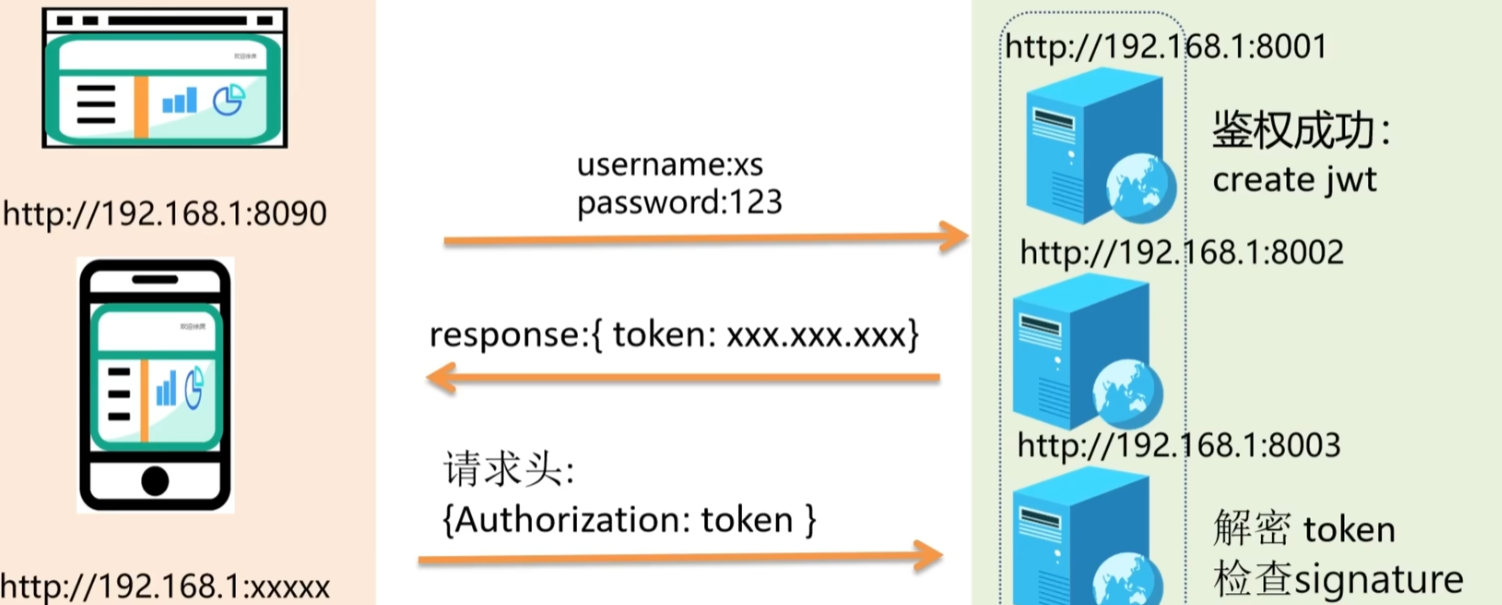
token
jwt令牌(json web token)
- 由三段信息组成:header.payload.signature
- header(头):包含了签名算法和token类型
- payload(负载数据):包含了数据
- signature(签名密钥):包含了经过base64编码后的header和payload,以及私钥
Mysql
常见的存储引擎
- InnoDB1
- 支持事务。
- 使用的锁粒度默认为行级锁,可以支持更高的并发;也支持表锁。
- 支持外键约束;外键约束其实降低了表的查询速度,增加了表之间的耦合度。
- MyISAM
- 不提供事务支持
- 只支持表级锁
- 不支持外键
- memory
- 数据存储在内存中总结
总结·
- MylISAM管理非事务表,提供高速存储和检索以及全文搜索能力,如果在应用中执行大量select操作,应该选择MyISAM
- InnoDB用于事务处理,具有ACID事务支持等特性,如果在应用中执行大量insert和update操作,应该选择InnoDB
建表时的注意事项
- 注意选择存储引擎,如果要支持事务需要选择lnnoDB。
- 注意字段类型的选择
- 对于日期类型如果要记录时分秒建议使用datetime,只记录年月日使用date类型
- 对于字符类型的选择,固定长度字段选择char,不固定长度的字段选择varchar,varchart比char节省空间但速度没有char快;
- 对于内容介绍类的长广文本字段使用text或longtext类型;
- 如果存储图片等二进制数据使用blob或longblob类型;
- 对金额字段建议使用DECIMAL;
- 对于数值类型的字段在确保取值范围足够的前提下尽量使用占用空间较小的类型,
- 主键字段建议使用自然主键,不要有业务意义,建议使用int unsigned类型,特殊场景使用bigint类型。
- 如果要存储text、blob字段建议单独建一张表,使用外键关联。
- 尽量不要定义外键,保证表的独立性,可以存在外键意义的字段。
- 设置字段默认值,比如:状态、创建时间等。
- 每个字段写清楚注释。
- 注意字段的约束,比如:非空、唯一、主键等。
树形表查询
树型表的标记字段是什么?
- 树型表的标记字段是parentid即父结点的id。
如何查询Mysql树型表?
- 当层级固定时可以用表的自链接进行查询。
- 如果想灵活查询每个层级可以使用mysql递归方法,使用with RECURSIVE 实现。(with RECURSIVE是mysql8之后才出现的)
数据对象模型
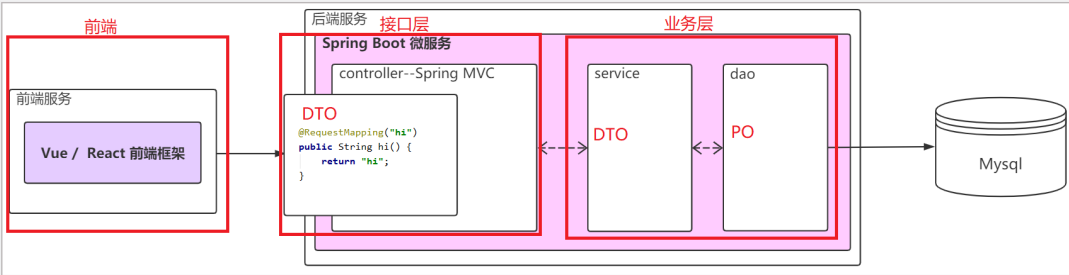
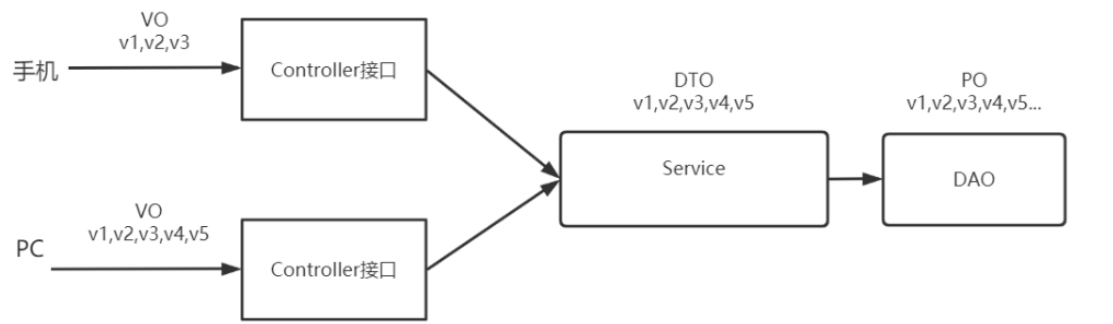
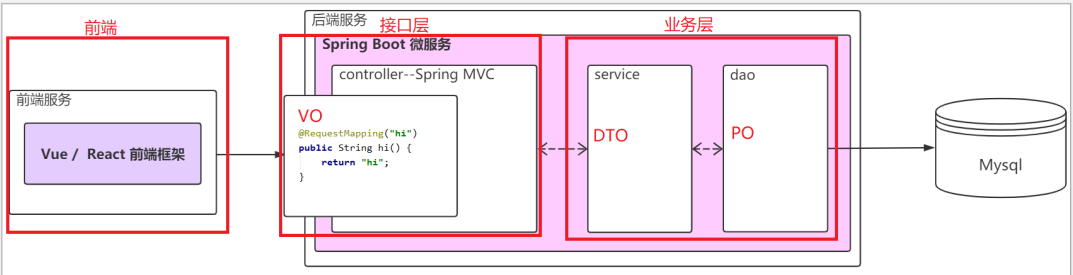
VO
- VO(View Object)视图对象,通常用于表示一个业务实体或者页面展示的内容。
- 通常用在前端和controller层的交互
- 如果是一个DTO对应一个VO,则DTO等价于VO,但是如果一个DTO对应多个VO,则展示层需要把VO转换为服务层对应方法所要求的DTO
- VO通常包含了多个属性,并且这些属性的类型和名称与业务相关。
- VO并不一定与数据库中的表结构相同,也不一定包含所有的属性。
DTO
- DTO(Data Transfer Object)数据传输对象
- 通常用在controller层和service层
- 如我们一张表有100个字段,那么对应的PO就有100个属性。但是我们界面上只要显示10个字段,客户端用WEB service来获取数据,没有必要把整个PO对象传递到客户端,这时我们就可以用只有这10个属性的DTO来传递结果到客户端,这样也不会暴露服务端表结构.到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO。
PO
- PO(Persistent Object)持久化对象,通常用于表示数据库中的表结构以及与之对应的实体类
- 通常用在dao层(数据访问层)
- PO通常包含了多个属性和对应的getter/setter方法,属性的类型和名称与表结构相对应。
- 将数据库中的数据映射为Java对象,方便程序对数据的操作。
其他
项目开发流程
- 产品人员设计产品原型。
- 讨论需求。
- 分模块设计接口。
- 出接口文档。
- 将接口文档给到前端人员,前后端分离开发。
- 开发完毕进行测试。
- 测试完毕发布项目,由运维人员进行部署安装。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 JyBlog🏀🐓!




