
商务智能课设
《商务智能应用方法》期末课程设计
基于历史数据的天气预测模型
组员:2115090116 卢家业 2115090118 覃庆烽
一、摘要
随着气候变化的加剧和极端天气事件的频发,准确的天气预测变得越来越重要。本文提出了一种基于历史数据的天气预测模型,旨在提高短期和中期天气预报的精度。该模型利用多年的气象观测数据,通过数据清洗、特征提取和机器学习算法,建立了一套完整的预测系统。我们选用了多种算法,包括线性回归、决策树、随机森林和深度神经网络,对比分析其在不同气象条件下的预测性能。研究表明,结合多种算法的集成模型在温度、降水量、风速等指标上的预测精度显著优于单一模型。特别是深度神经网络在处理复杂非线性关系方面表现出色。模型经过交叉验证和实地测试,结果显示其在实际应用中具有较高的可靠性和稳定性。本研究的创新点在于利用历史数据的多样性和丰富性,结合先进的机器学习技术,为天气预测提供了一种有效的解决方案,为相关领域的进一步研究和应用提供了参考依据。
二、研究背景与意义
全球气候变化的加剧和人类活动对环境的影响日益显著,天气预测的重要性愈加凸显。准确的天气预报不仅能够帮助人们合理安排生产和生活,还能够在极端天气事件如台风、暴雨、干旱等发生时,提供及时的预警,减少灾害造成的损失。传统的天气预报方法主要依赖于数值天气预报模型(NWP),这些模型基于物理方程和大气动力学原理,进行大规模的计算和模拟。然而,数值天气预报模型的精度受到多种因素的限制,包括初始条件的不确定性、模型的参数化方法以及计算资源的限制。
近年来,随着大数据技术和机器学习算法的迅速发展,基于历史数据的天气预测方法逐渐受到关注。通过利用大量的气象观测数据,机器学习算法能够从中提取出隐藏的模式和规律,为天气预测提供一种新的方法。相比传统的数值天气预报模型,基于历史数据的预测方法具有计算效率高、适应性强等优点,尤其在短期和中期天气预报中展现出很大的潜力。
本研究的目的在于开发一种基于历史数据的天气预测模型,通过分析多年的气象观测数据,利用数据驱动的方法提高天气预报的准确性和可靠性。具体而言,我们希望通过以下几方面实现研究目标:
- 数据整合与清洗:收集并整合多年来的气象观测数据,进行数据清洗和预处理,确保数据的完整性和一致性。
- 特征提取与选择:利用数据挖掘技术,从气象数据中提取出与天气变化密切相关的特征,为模型训练提供高质量的输入。
- 模型构建与优化:采用多种机器学习算法,包括线性回归、决策树、随机森林和深度神经网络,构建预测模型,并通过交叉验证和参数优化提高模型性能。
- 结果验证与评估:通过历史数据的回测和实际天气情况的比较,验证模型的预测效果,评估其在不同气象条件下的适用性和稳定性。
本研究具有重要的理论和实际意义。从理论上讲,探索基于历史数据的天气预测方法有助于丰富和发展天气预报领域的研究方法和技术手段;从实际应用的角度看,精准的天气预报能够为农业生产、交通运输、防灾减灾等领域提供重要的参考,具有广泛的社会和经济效益。通过本研究,我们希望为气象预测领域提供一种有效的解决方案,推动天气预报技术的发展和应用。
三、数据来源
天气预报网:http://www.tianqihoubao.com/
爬取了四组数据
第一组:2021年1月份-6月份北京市的天气预报 链接:http://www.tianqihoubao.com/lishi/beijing/month/202107.html
第二组:2021年1月份-6月份南宁市的天气预报 链接:http://www.tianqihoubao.com/lishi/nangning/month/202107.html
第三组:2021年1月份-6月份长春市的天气预报 链接:http://www.tianqihoubao.com/lishi/changchun/month/202107.html
第四组:2021年1月份-6月份广州市的天气预报 链接:http://www.tianqihoubao.com/lishi/guangzhou/month/202107.html
四、数据存储与预处理
代码
1 | import pandas as pd |
这段代码主要完成了以下操作:
- 导入了Pandas库,并读取了四个CSV文件:’BJ.csv’, ‘CC.csv’, ‘GZ.csv’, ‘NN.csv’,使用GBK编码。
- 定义了一个名为
deal的函数,用于处理数据框。这个函数的功能包括:
- 重命名数据框的列为[‘日期’, ‘天气情况’, ‘气温’, ‘风力’]。
- 将’气温’列按照”/“进行拆分,分成’最低温’和’最高温’两列。
- 将’天气情况’列按照”/“进行拆分,分成’去初天气’和’后来天气’两列。
- 去除’最低温’和’最高温’列中的’℃’字符。
- 将’最低温’和’最高温’列转换为数值类型。
- 将日期列拆分为’年’、’月’、’日’三列。
- 最后返回处理后的数据框。
- 对四个数据框分别调用
deal函数进行处理,并将处理后的结果重新赋值给相应的数据框bj_df、cc_df、gz_df、nn_df。- 将处理后的四个数据框分别写入新的CSV文件:’BJ2.csv’, ‘CC2.csv’, ‘GZ2.csv’, ‘NN2.csv’,并使用GBK编码。
总体来说,这段代码的主要作用是读取四个CSV文件,对每个文件进行特定的数据处理(包括重命名列、拆分列、数据清洗、类型转换等),然后将处理后的结果写入新的CSV文件中。
五、建立数据挖掘模型
聚类分析
代码部分
1 | import pandas as pd |
代码解释
- 导入所需的库,包括Pandas用于数据处理,re用于正则表达式处理,sklearn中的KMeans用于聚类分析,matplotlib.pyplot和seaborn用于数据可视化,以及LabelEncoder用于对分类变量进行编码。
- 从文件’NN2.csv’中加载数据,并对列名进行重命名,以处理可能存在的编码问题。
- 定义了一个函数
clean_encoding_issues,用于清理文本中的编码问题,例如将一些特定编码转换为可读的文本。- 对相关列应用
clean_encoding_issues函数,清理数据中的编码问题。- 将温度列拆分为最低温度和最高温度,并转换为浮点数类型。
- 将日期列转换为datetime格式,并丢弃原始的温度列。
- 使用LabelEncoder对分类变量进行编码,包括天气情况、风力等。
- 选择用于聚类的特征,包括最低温度、最高温度和编码后的天气情况。
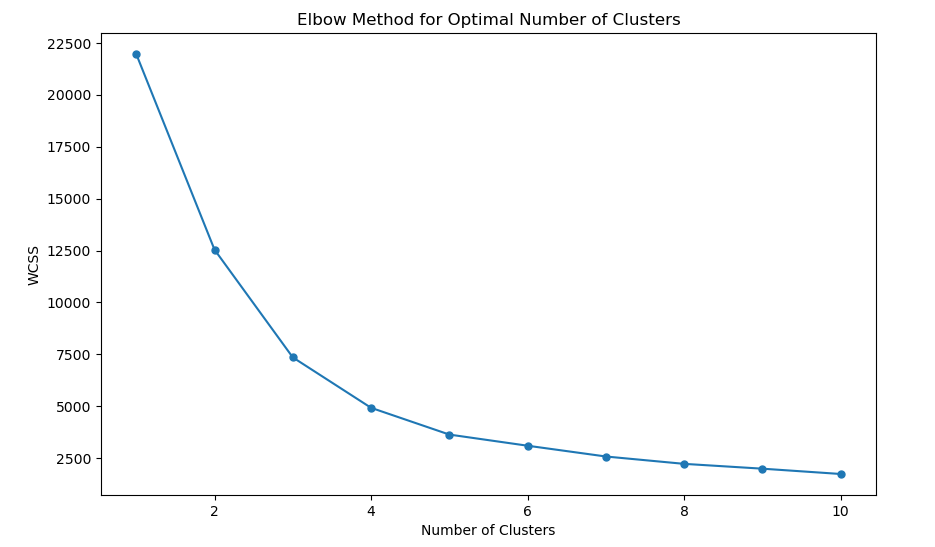
- 使用肘部法则(elbow method)确定最佳聚类数,即通过循环尝试不同聚类数,计算每个聚类数下的WCSS(Within-Cluster Sum of Squares)并绘制肘部法则图。
- 根据肘部法则图选择最佳聚类数,这里假设最佳聚类数为4。
- 使用最佳聚类数对KMeans模型进行训练,并将每个样本分配到对应的簇中。
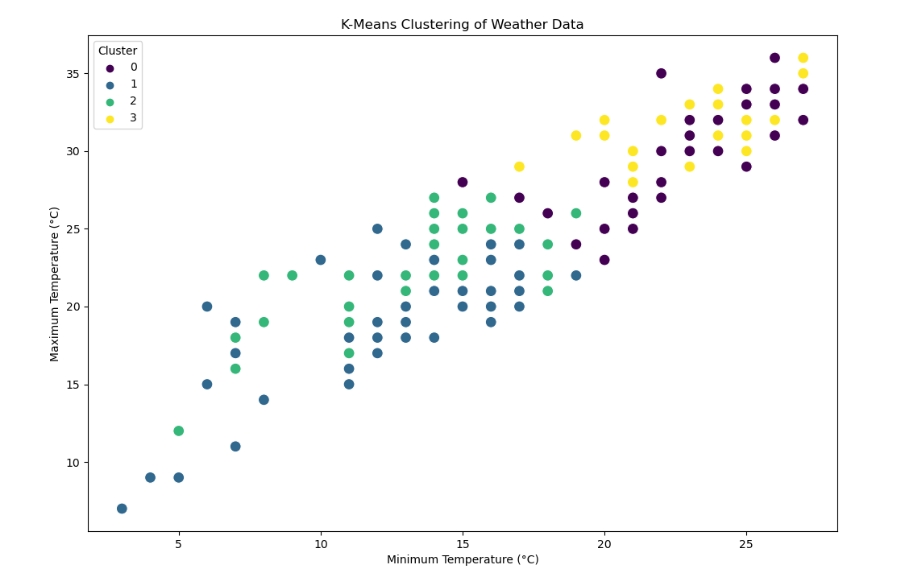
- 绘制聚类结果的散点图,展示最低温度和最高温度之间的关系,不同簇用不同颜色表示。
总体来说,这段代码实现了对天气数据进行聚类分析,包括数据清洗、特征选择、聚类模型训练和结果可视化。通过聚类分析,可以发现数据中的天气情况在最低温度和最高温度下的分布情况。
图片
六、可视化展示与分析
课题一
各城市风力等级分布时间环形图
代码
1 | import pandas as pd |
可视化
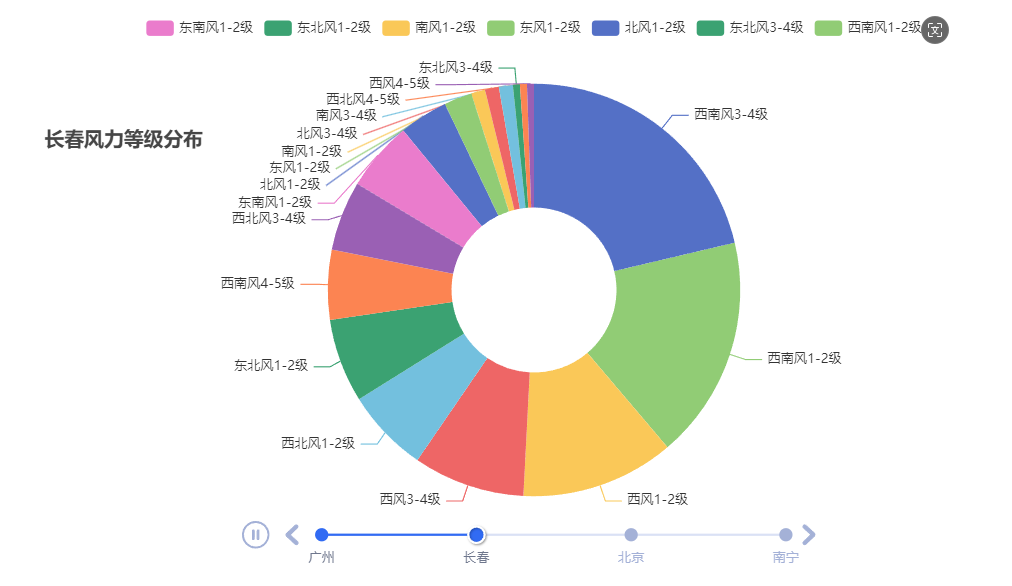
总结
由风力等级分布时间环形图可以看出
广州大部分的时间都是1-2级的北风
南宁以南风、东南风、东北风为主
而长春和北京各种风错综复杂
课题二
各城市的天气变化率
代码
1 | import pandas as pd |
可视化
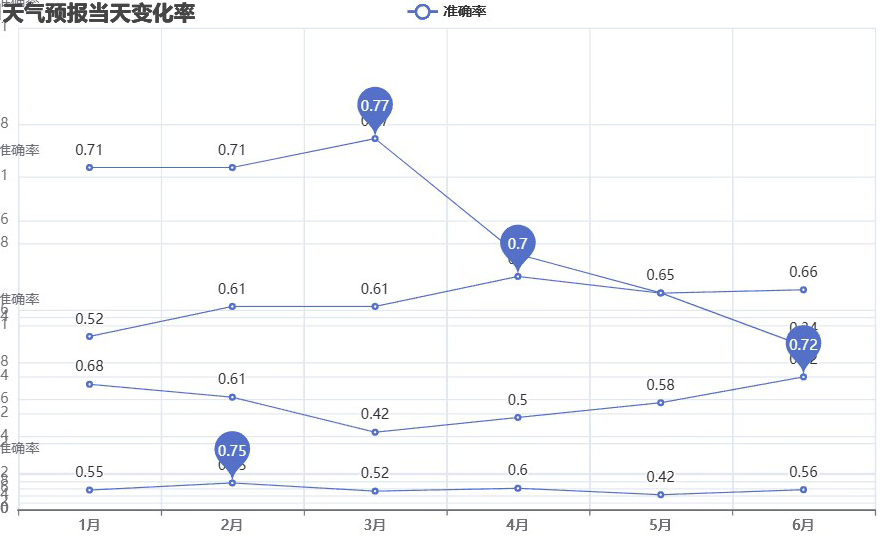
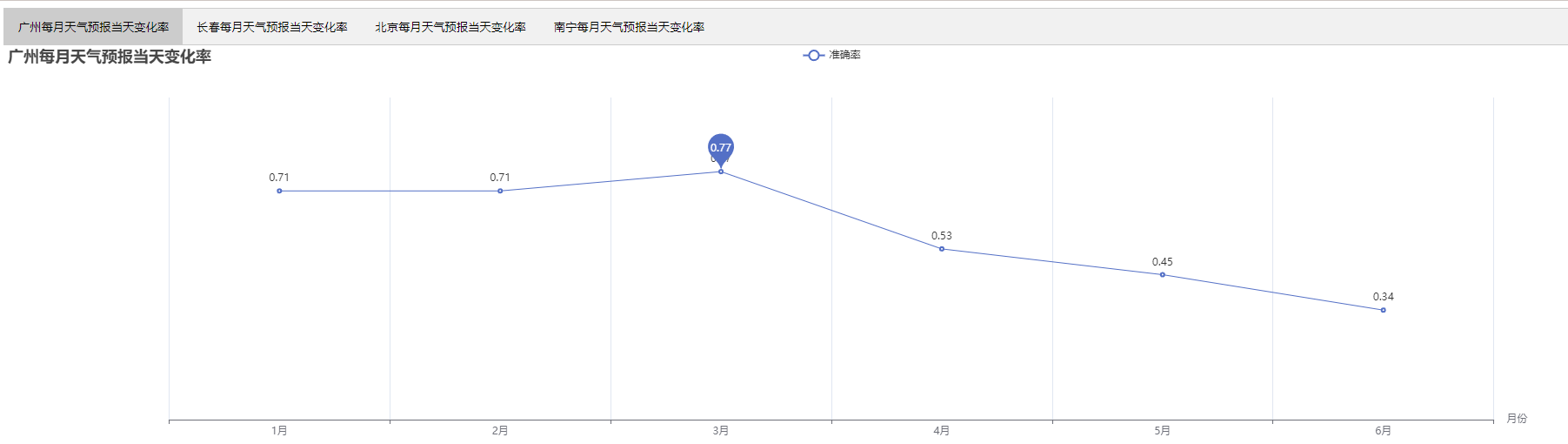
总结
由该天气变化率组合图可以看出
广州在3月份的天气变化无常,6月份的天气相对稳定
长春整体天气变化情况都比较稳定,没有太大的浮动
北京在6月份的天气变化无常,3月份的天气相对稳定
南宁天气上下波动,成心率变化
课题三
各城市每月带有雨的天气情况占比时间环形图
代码
1 | import pandas as pd |
可视化
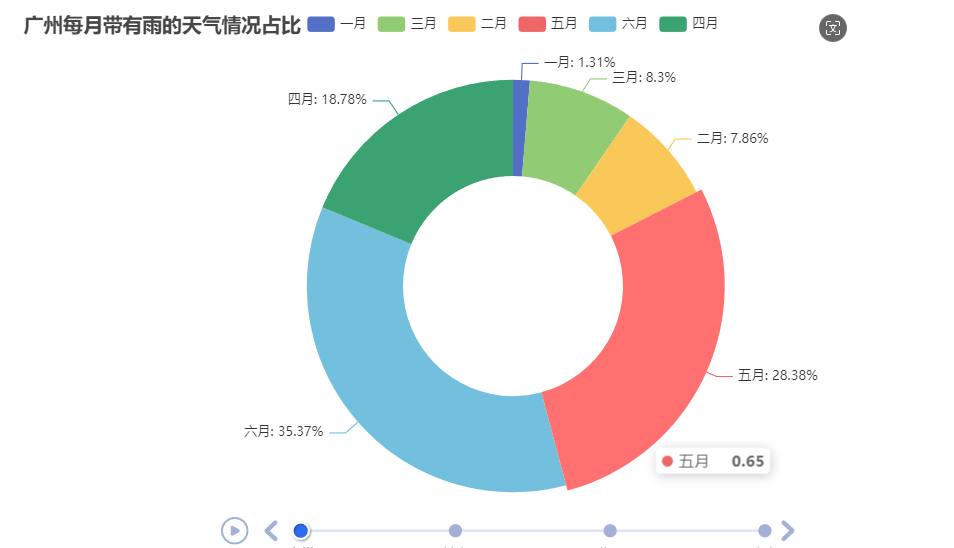
总结
由该雨天时间轮播图可以看出
各城市的雨季都集中在6月份
各城市的旱季都集中在2月份
课题四
各个城市的天气最低最高温情况
代码
1 | import pandas as pd |
可视化
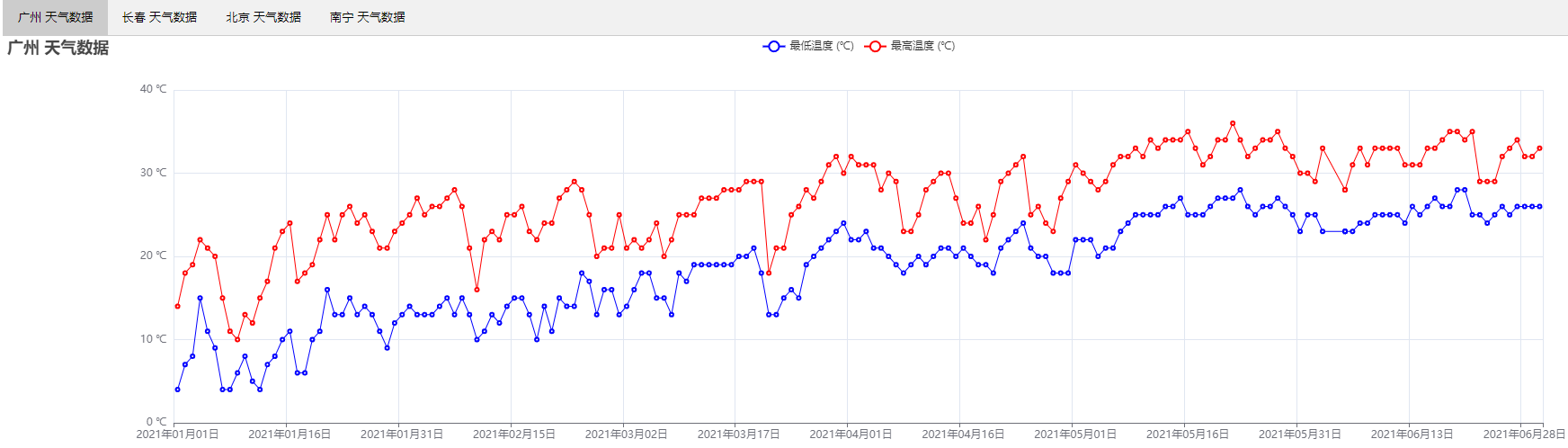
总结
由图可以看出
广州天气整体偏热 最高气温大部分大于20摄氏度
长春天气在13月天气低至零下 在4月份的时候才开始回暖3月天气也低至零下 但是相对长春 温度整体较高 整个折线图呈较明显的上升趋势
北京天气在1
南宁天气起伏不定 部分天数出现较大起伏 可能出现前一天与后一天温差在10摄氏度的情况




