Mysql
小黑框下的操作
登录mysql
- mysql -u用户名 -p密码 -h要连接的mysql服务器IP地址(默认是127.0.0.1) -p端口号(默认是3306)
退出mysql
- exit
- quit
卸载mysql
- net stop mysql
- mysqld -remove mysql
- 删除mysql目录及相关的环境变量
SQL通用语句
- SQL语句可以单行或多行书写,以分号结尾。
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
- 单行注释:– 注释或#注释
- 多行注释:/* 注释 */
DDL
- DDL(Data Definition Language)数据定义语言,用来定义数据库对象︰数据库,表,列等
操作数据库
查询:show databases;(查询所有数据库)
select database();(查询当前使用的数据库)
创建:create database 数据库名称;
create database if not exists 数据库名称;
删除:drop database 数据库名称;
drop database if exists 数据库名称;
使用:use 数据库名称;
操作表
查询:show tables;(查询当前数据库下所有的表名称)
desc 表名称;(查询表结构)
show create table 表名称(查看建表语句)
创建:create table 表名(
字段名1 数据类型1,
字段名2 数据类型2,
….
字段名n 数据类型n
);
删除:drop table 表名;
drop table if exists 表名;
修改:alter table 表名 rename to 新表名;(修改表名)
alter table 表名 add 列名 数据类型;(添加一列)
alter table 表名 modify 列名 新数据类型;(修改数据类型)
alter table 表名 change 列名 新列名 新数据类型;(修改列名和数据类型)
alter table 表名 drop 列名;(删除列)
DML
DML(Data Manipulation Language)数据操作语言,用来对数据库中表的数据进行增删改
增加:insert into 表名(列名1,列名2,…) values(值1,值2,…);(给指定列添加数据)
insert into 表名 values(值1,值2,….值n);(给全部列添加数据)
删除:delete from 表名 [where 条件]; (删除数据)
修改:update 表名 set 列名1=值1,列名2=值2,… [where 条件];(修改数据)
DQL
- DQL(Data Query Language)数据查询语言,用来查询数据库中表的记录(数据)
基础查询
- 查询所有字段
- select * from 表名;
- 查询指定字段
- select 字段列表 from 表名;
- 去除重复记录(distinct)
- select distinct 字段列表 from 表名;
- 起别名(as)
- select 字段 as 别名 from 表名;
条件查询
select 字段列表 from 表名 where 条件列表;排序方式: - 升序(默认):asc - 降序:desc1
2
3
4
5
## 排序查询
- ```sql
select 字段列表 from 表名 order by 排序字段名1[排序方式1],排序字段名2[排序方式2]...;注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
聚合函数
- 概念:将一列数据作为一个整体,进行纵向计算。
- select 聚合函数(列名) from 表;
- 聚会函数:
- count():统计数量
- max():最大值
- min():最小值
- sum():求和
- aavg():平均值
- 注意:null值不参与所有聚合函数运算
分组查询
select 字段列表 from 表名 [where 分组前条件限定] group by 分组字段名 [having 分组后条件过滤];1
2
3
4
5
6
7
8
9
10- 注意:
- 分组之后,查询的字段应为聚合函数和分组字段,查询其他字段无任何意义。
- 执行顺序:where>聚合函数>having
- where是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
- 可判断的条件不一样: where不能对聚合函数进行判断,having可以。
## 分页查询
- ```sql
select 字段列表 from 表名 limit 起始索引,查询条目数;- 起始索引:从0开始
- 计算公式:起始索引=(当前页码-1)*每页显示的条数
DCL
- DCL(Data Conttol Language)数据控制语言,用来定义数据库的访问权限和安全级别及创建用户
约束
- 约束的概念:约束是作用于表中列上的规则,用于限制加入表的数据
- 约束的作用:约束的存在保证了数据库中数据的正确性、有效性和完整性
- 添加约束可以在建表时添加,也可以在建完表之后再添加
非空约束
- 关键字:not null
- 描述:保证列中所有数据不能有null值
唯一约束
- 关键字:unique
- 描述:保证列中所有数据各不相同
主键约束
关键字:primary key
描述:主键是一行数据的唯一标识,要求非空且唯一
添加:
1
alter table 表名 add primary key(字段名);
删除:
1
alter table 表名 drop primary key;
检查约束
- 关键字:check
- 描述:保证列中的值满足某一条件
默认约束
关键字:default
描述:保存数据时,未指定值则采用默认值
添加:
1
alter table 表名 alter 列名 set default 默认值;
删除:
1
alter table 表名 alter 列名 drop default;
外键约束
关键字:foreign key
描述:外键用来让两个表的数据之间建立链接,保证数据的一致性和完整性
建表时添加:
1
[constraint] [外键名称] foreign key(外键列名) references 主表(主表列名)
建完表之后添加:
1
alter table 表名 add constraint 外键名称 foreign key (外键列名) references 主表(主表列名);
删除:
1
alter table 表名 drop foreign key 外键名称;
自动增长
- 关键字:auto_increment
- 注意:当列是数字类型并且唯一约束才能用
数据库设计
软件的研发步骤
- 需求分析:(产品经理 -> 产品原型)
- 设计:(架构师,开发工程师 -> 软件结构设计,数据库设计,接口设计,过程设计)
- 编码:(开发工程师)
- 测试:(测试工程师)
- 安装部署(运维工程师)
数据库设计
- 概念
- 数据库设计就是根据业务系统的具体需求,结合我们所选用的DBMS,为这个业务系统构造出最优的数据存储模型。
- 建立数据库中的表结构以及表与表之间的关联关系的过程。
- 有哪些表?表里有哪些字段?表和表之间有什么关系?
- 设计步骤
- 需求分析(数据是什么?数据具有哪些属性?数据与属性的特点是什么)
- 逻辑分析(通过ER图对数据库进行逻辑建模,不需要考虑我们所选用的数据库管理系统)
- 物理设计(根据数据库自身的特点把逻辑设计转换为物理设计)
- 维护设计(1.对新的需求进行建表;2表优化)
表关系
- 一对一
- 如:用户和用户详情
- 实现方式:在任意一方加入外键,关联另一方主键,并且设置外键为唯一(UNIQUE)
- 一对多(多对一)
- 如:部门和员工
- 实现方式:在多的一方建立外键,指向一的一方的主键
- 多对多
- 如:商品和订单
- 实现方式:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
多表查询
连接查询
内连接:
相当于查询表之间交集的数据
隐式内连接:
select 字段列表 from 表1,表2...where 条件;1
2
3
4
5
- 显示内连接:
- ```sql
select 字段列表 from 表1 [inner] join 表2 on 条件;
外连接
左外连接
左外连接:相当于查询A表所有数据和交集部分数据
select 字段列表 from 表1 left [outer] join 表2 on 条件;1
2
3
4
5
6
7
- 右外连接
- 右外连接:相当于查询B表所有数据和交集部分数据
- ```sql
select 字段列表 from 表1 right [outer] join 表2 on 条件;
子查询
- 查询中嵌套查询,称嵌套查询为子查询
多行单列
单行单列:作为条件值,使用=!=><等进行条件判断
select 字段列表 from 表 where 字段名 条件 (子查询)1
2
3
4
5
6
7
### 多行单列
- 多行单列:作为条件值,使用in 等关键字进行条件判断
- ```sql
select 字段列表 from 表 where 字段名 in (子查询)
多行多列
多行多列:作为虚拟表
select 字段列表 from(子查询)where 条件;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
## 组合查询
### union
- UNION 操作符合并两个或多个 SELECT 语句的结果。
- 注意:UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
- 默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
- ```sql
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;
常用函数
字符串
- length(str):计算字符串长度
- reverse(str):反转字符串
- concat(str1,str2):拼接字符串
- concat_ws(分隔符,str1,array(str2,str3,…)):带分隔符拼接字符串
- substr(str,开始位置,截取长度):截取字符串
- split(str,regex):分割字符串(mysql没有此函数)
- regexp运算符:是正则表达式(regular expression)的缩写,正则表达式在搜索字符串时非常强大
- ^表示字符串开头
- ¥表示字符串结尾
- |表示逻辑上的or,可以给出多个搜索模式
- []表示任意在括号里列举的单字符
- [-]表示任意在括号内范围内的单字符
时间
- current_date():显示当前日期
- datediff(‘date1’,’date2’):计算日期差,日期格式要求”yyyy-MM-dd HH:mm:ss“ 或者”yyyy-MM-dd”
- date_add(date,增加天数):日期增加
- date_sub(date,减少天数):日期减少
- day(date):返回date中的day值
- month(date):返回date中的month值
- year(date):返回date中的year值
数学
- round(double a):四舍五入取整
- round(double a,int b):保留b位小数
- rand():在0-1之间随机取值
其他
if(boolean testCondition,True,FalseOrNull):三元表达式
case的用法
1
2
3
4
5
6
7case
when 表达式1 then 值1
when 表达式2 then 值2
when 表达式3 then 值3
......
else 其他值
endnvl(value1,default_value):空值转换函数
事务
事务简介
- 数据库的事务((Transaction)是一种机制、一个操作序列,包含了一组数据库操作命令
- 事务把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么同时成功,要么同时失败
- 事务是一个不可分割的工作逻辑单元
事务的语法
begin; #开始事务 .....#要执行的操作 commit;#提交事务 rollback;#回滚事务
事务的四大特征(ACID)
- 原子性(Atomicity):事务是不可分割的最小操作单位,要么同时成功,要么同时失败
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态
- 隔离性(lsolation):多个事务之间,操作的可见性
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
索引
索引(index)是帮助数据库高效获取数据的数据结构。
优点
- 提高数据查询的效率,降低数据库的Io成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点
- 索引会占用存储空间。
- 索引大大提高了查询效率,同时却也降低了insert、
update. delete的效率。
结构
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平常所说的索引,如果没有特别指明,都是指默认的B+Tree结构组织的索引。
B+Tree(多路平衡搜索树)
语法
- 创建索引:create [ unique ] index 索引名 on 表名(字段名,…);
- 查看索引:show index from 表名;
- 删除索引:drop index 索引名 on 表名;
注意
- 主键字段,在建表时,会自动创建主键索引。
- 添加唯一约束时,数据库实际上会添加唯一索引
主从复制
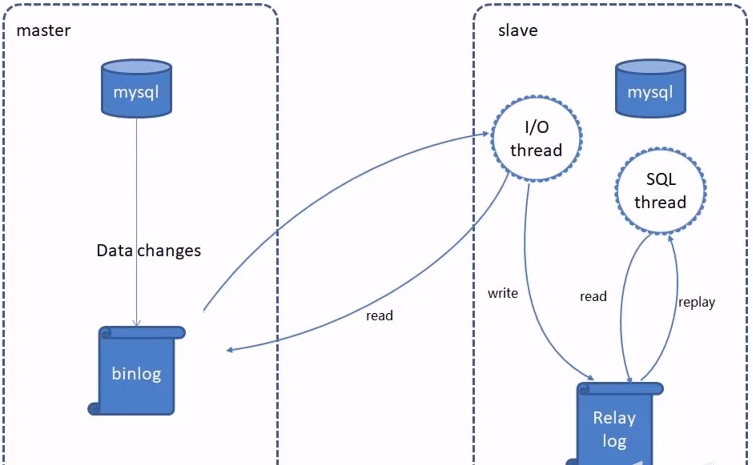
介绍
- MNySQL主从复制是一个异步的复制过程,底层是基于Nysql数据库自带的二进制日志功能。
- 就是一台或多台MySQL数据库(slave,即从库)从另一台MysQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。
- MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
复制过程
- master将改变记录到二进制日志( binary log)
- slave将master的binary log拷贝到它的中继日志( relay log)
- slave重做中继日志中的事件,将改变应用到自己的数据库中